
Classifier to Segmentation
Deep Learning Final Project by Abhay Deshpande, Andrew Mazzawi, Alan Wu, and Cindy Zou
Deep Learning Final Project by Abhay Deshpande, Andrew Mazzawi, Alan Wu, and Cindy Zou
We aim to solve the problem of object segmentation, where the input is an image and class label such as “cat” and the output is a mask where objects of that class are present in the image. However, we want to only use a pre-trained classification model with no additional training for segmentation, by checking which pixels of the image were used by the model to classify it as a particular label.
Current state of the art object segmentation methods involve training a deep neural network on a segmentation dataset. DeconvNet in particular appends deconvolutional layers after a convolutional neural network that aim to reverse the convolutions to obtain the input pixels that contributed to a class. However, Simonyan, et. al. in their paper “Deep inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps” proposed a method for doing this same computation with only a pre-trained classification model and no additional training for segmentation. They additionally proved that their method is equivalent to deconvolutions except when dealing with a ReLU layer. They use the gradient of a class probability with respect to an input pixel as a proxy for how important the pixel is for identifying that class, creating a saliency map, which can then be converted into a segmentation mask. A second method, guided backpropagation, tries to improve upon Simonyan, et. al.’s work. We replicate Simonyan, et. al.’s method and compare it in detail to guided backpropagation on the COCO segmentation challenge. We were able to achieve high IOU compared to ground truth masks on images with one large object, but lower IOU on images with many or small objects.
Pipeline Summary
1. Get detected classes with TResNet (multi-class classifier trained on COCO. Input: image. Output: probabilities for each class)
a. Run the classification model forward on image to get class probabilities
b. Get top k=20 most likely classes
c. Filter for classes with probability > threshold=0.75

2. For each detected class:
a. Calculate the gradient of the class probability w.r.t. the input image
i. Method 1: “vanilla” gradient backpropagation
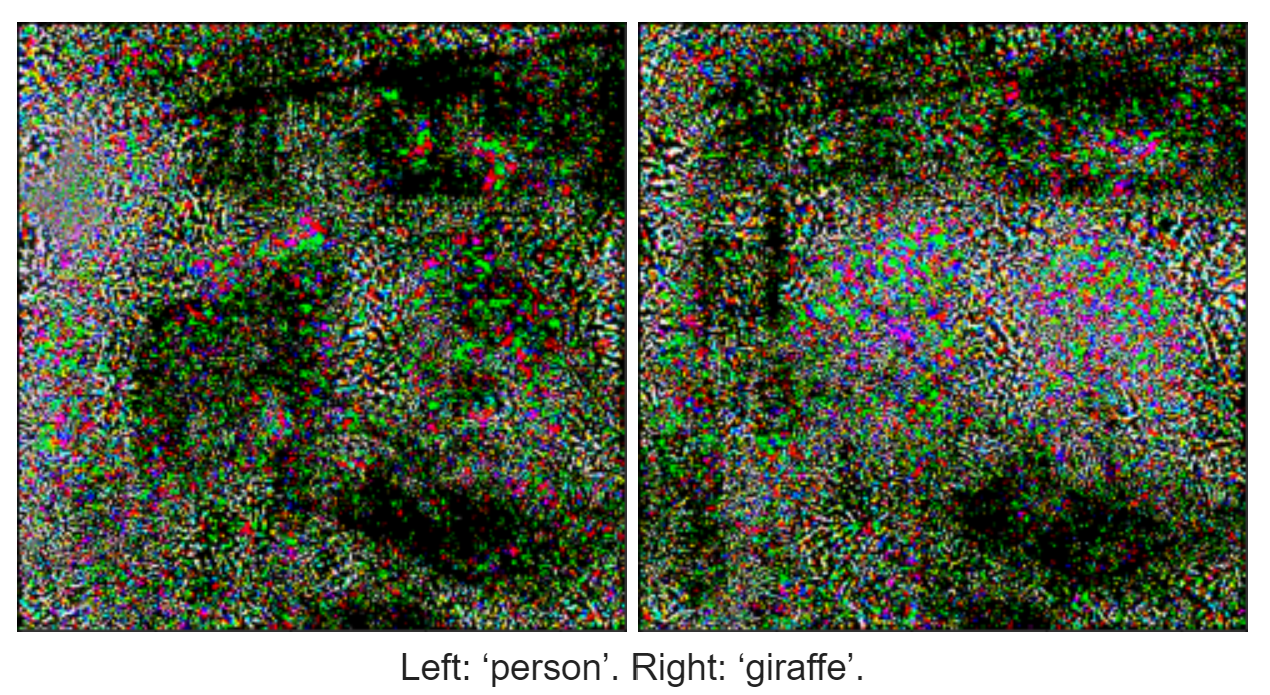
ii. Method 2: guided backpropagation

b. Convert the gradient to a saliency map by taking the absolute value of the gradient and taking the max absolute value across the channels for each pixel


c. Convert the saliency map to a segmentation mask
i. Method 1: using the GraphCut library (
1. Compute the foreground seed, a mask of pixels with saliency above the 95th percentile, and the background seed, a mask of pixels saliency below the 30th percentile


Foreground (left) and background (right) from vanilla gradient. Top: ‘person’. Bottom: ‘giraffe’.


Foreground (left) and background (right) from guided backpropagation. Top: ‘person’. Bottom: ‘giraffe’.
2. Input the image, foreground seed, and background seed into the GraphCut library to get a foreground mask




ii. Method 2: our own recursive expansion algorithm (see below)
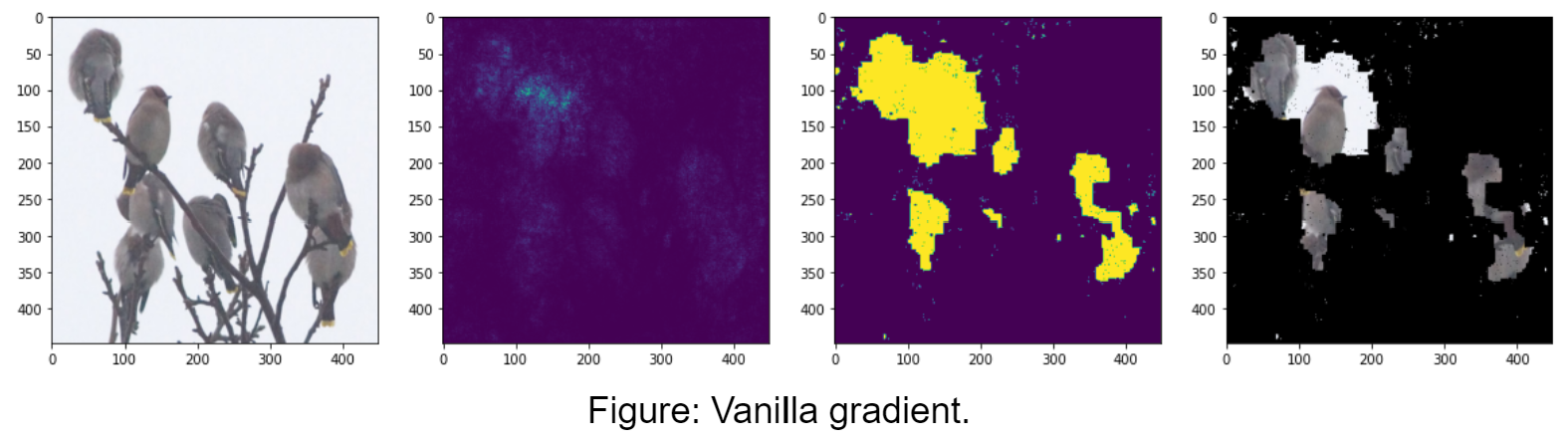
"Vanilla" Gradient Backpropagation
This method is called “vanilla” because the idea behind it is simple. Simonyan, et. al. proposed that if the gradient of a class’s probability with regard to an input pixel is large, then that means changing the pixel would cause a large change in the class’ probability, so it must be important for identifying that class. Thus the absolute value of the gradient of a class’s probability with regard to all the pixels in an image is a saliency map for that class. We can get this gradient easily using PyTorch Autograd by calling backward() on the model output, which populates the gradient of the output with regard to each layer, and then getting the gradient of the input image.
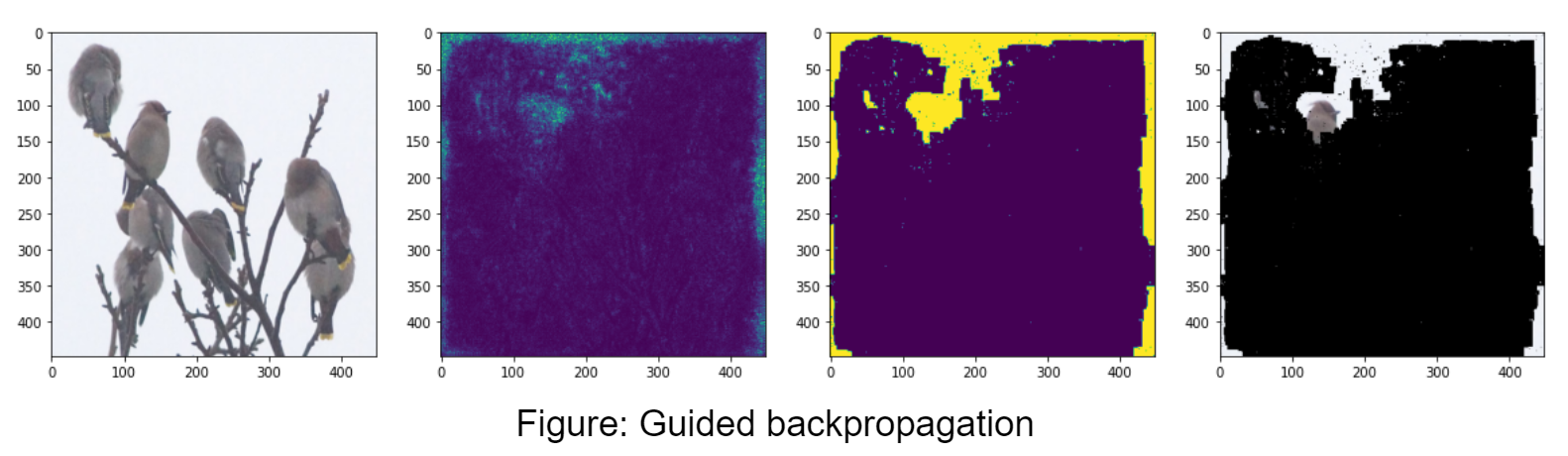
Guided Backpropagation
Guided backpropagation aims to solve some of the shortcomings of the vanilla method, where the saliency map is fuzzy and pixels that negatively correlate with the class still have high saliency. We backpropagate the same way, except for a ReLU layer we zero out gradient entries that are either negative or whose pixel was zeroed out in the ReLU forward pass. Intuitively we want to zero out negative gradient pixels because they negatively correlate with the output class. Simonyan, et. al. showed that vanilla gradient backpropagation is equivalent to deconvolutions, except when backpropagating through a ReLU layer. Guided backpropagation’s treatment of ReLU layers is closer to that of deconvolutions.



Gradient to Saliency Map
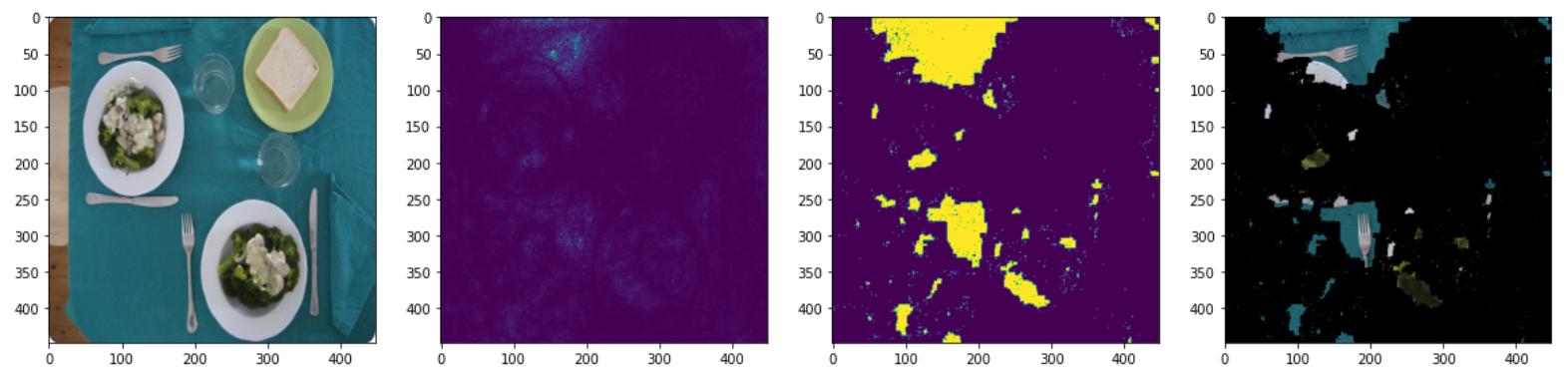
We used the method proposed by Simonyan et. al., which is to take the absolute value of the gradient and flatten the channels by taking the max absolute value across channels for each pixel. The absolute value is the magnitude of the gradient, or, how important it is for the classification. We also explored not taking the absolute value, but this resulted in masks with holes, as shown in the figures below. The figures contain, from left to right: input image, saliency map, mask, masked image. Detected class: “bird.”

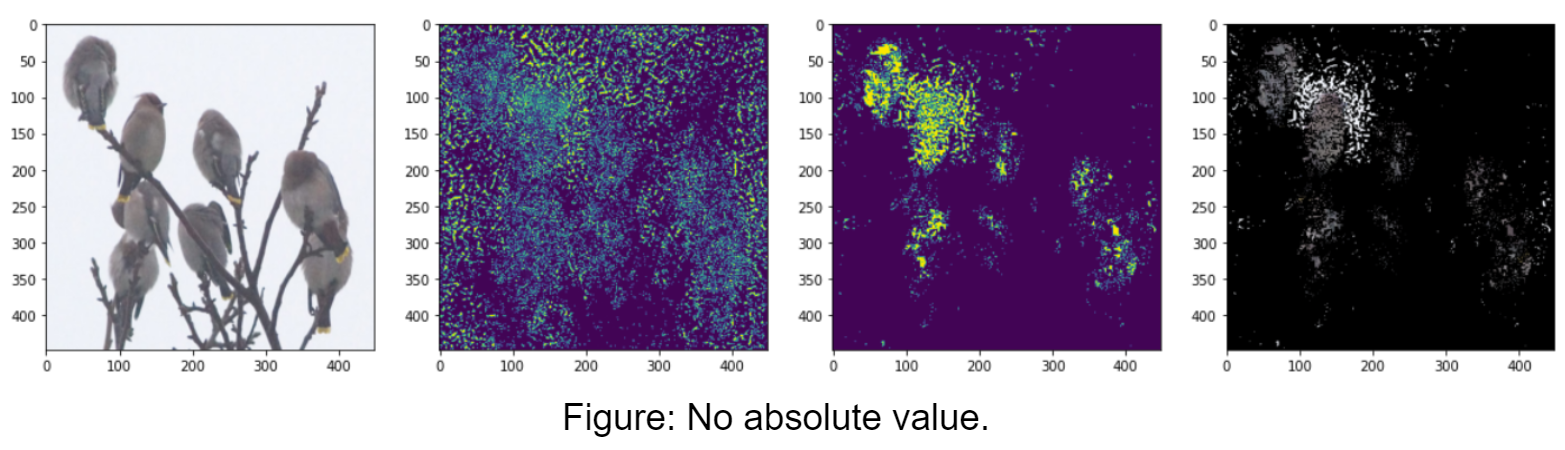
Saliency Map to Segmentation Mask
Using the saliency map of the given image, the program extracts pixels with an intensity that is at the bottom 30% to and pixels at or above the top 90% to create a background and foreground image respectively. Then by using the foreground image, we iterate through the top 50 pixels with the highest saliency and recursively expand outwards to pixels above a certain threshold in an attempt to create a mask. This approach generated an inaccurate mask for some images and for others nothing was generated. To fix this, we used a library that implemented the Graph Cut algorithm to segment the image. This implementation of graph cut works by taking the strokes of the seed image that mark foreground and background and perform a cut on the image. The cut is performed by choosing the cut with the least cumulative weight, where weight of an edge is based on the inverse squared difference between neighboring pixels, such that pixels (pixels in the graph are represented by the nodes) with large differences have low weight and vice versa. After the cuts are created, the mask is output separating the foreground and background.
For evaluation, we combined the segmentation masks for all detected classes within an image into a single mask for that image. Then, we compared our generated mask for an image to its ground truth mask. We calculated how well our generated masks were by calculating the Intersection over Union value between the generated masks and their respective ground truth masks. An Intersection over Union value is the amount of intersecting area between the two masks divided by the union of the two masks’ area. Typically, having an IoU value greater than 0.5 is considered good.
Raw Image
Raw images are taken from the COCO dataset and transformed to be 448 pixels wide and tall.
Truth Mask
These images are the raw images overlaid with the ground truth segmentation masks.
Generated Mask
These images are the raw images overlaid with the segmentation masks that we generated with vanilla gradient backpropagation. These images are labeled with their Intersection over Union (IoU) values, which are calculated in comparison to their respective ground truth masks.


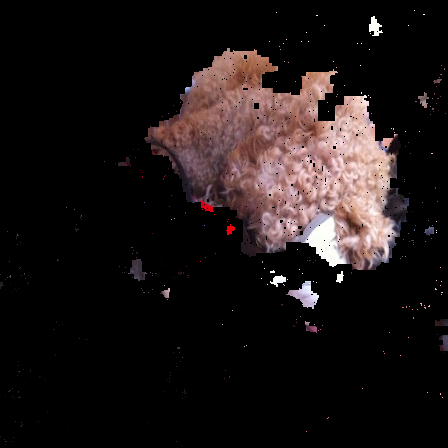



























As shown in the evaluation images, we get mixed results for the IOU. Images with a single large object generally have high IOU, while images with many different objects or small objects tend to have lower IOU. We could have made our masks more precise by running the GraphCut algorithm on multiple scaled versions of the image to better capture small objects. We could also use some techniques to reduce noise.
Sometimes saliency is highly concentrated on one area of an object, such as a person’s face or the tip of a fork
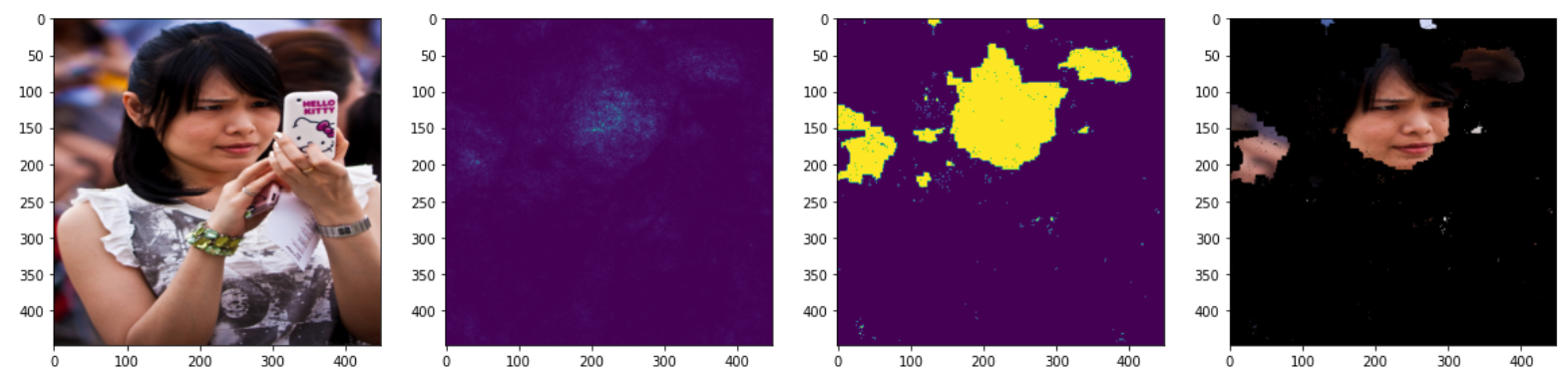
Guided backpropagation seems to do about the same or worse compared to vanilla gradient with our particular method of computing masks. This could be because zeroing out negatives in the backpropagation loses important information. It could also be that our method of computing the mask isn’t suited for guided backpropagation, since it tends to highlight edges. Other papers have instead used an edge detection algorithm to get the outlines of objects.
Dataset
Tsung-Yi Lin, Maire, M., Belongie, S. J., Bourdev, L. D., Girshick, R. B., Hays, J., … Zitnick, C. L. (2014). Microsoft COCO: Common Objects in Context. CoRR, abs/1405.0312. Retrieved from http://arxiv.org/abs/1405.0312
2014 Val images and annotationsClassifier
https://github.com/Alibaba-MIIL/ML_DecoderReferences
Simonyan, Karen, Andrea Vedaldi, and Andrew Zisserman. “Deep inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps.” arXiv.org, April 19, 2014. https://arxiv.org/abs/1312.6034.
https://arxiv.org/pdf/1312.6034.pdfZeiler, Matthew D., and Rob Fergus. “Visualizing and Understanding Convolutional Networks.” ArXiv.org, 28 Nov. 2013, arxiv.org/abs/1311.2901. Accessed 14 Dec. 2022.
https://arxiv.org/abs/1311.2901Zabriskie, Nathan. “Nathanzabriskie/Graphcut: Graph Cut Image Segmentation with Custom GUI.” GitHub, October 1, 2017. https://github.com/NathanZabriskie/GraphCut.
https://github.com/NathanZabriskie/GraphCutGuerzhoy, Michael. “CSC321: Introduction to Machine Learning and Neural Networks (Winter 2016).” CSC321: Introduction to machine learning and neural networks (winter 2016). Accessed December 14, 2022. https://www.cs.toronto.edu/~guerzhoy/321/.
https://www.cs.toronto.edu/~guerzhoy/321/lec/W07/HowConvNetsSee.pdfDraelos, Rachel. “CNN Heat Maps: Saliency/Backpropagation.” Glass Box, 21 June 2019, glassboxmedicine.com/2019/06/21/cnn-heat-maps-saliency-backpropagation/. Accessed 14 Dec. 2022.
https://glassboxmedicine.com/2019/06/21/cnn-heat-maps-saliency-backpropagation/Draelos, Rachel. “CNN Heat Maps: Gradients vs. DeconvNets vs. Guided Backpropagation.” Glass Box, 6 Oct. 2019, glassboxmedicine.com/2019/10/06/cnn-heat-maps-gradients-vs-deconvnets-vs-guided-backpropagation/. Accessed 14 Dec. 2022.
https://glassboxmedicine.com/2019/10/06/cnn-heat-maps-gradients-vs-deconvnets-vs-guided-backpropagation/